TurbOS®: The HPC Platform That Unifies Simulation and AI Workloads
Run complex simulation and AI workloads in one seamless environment - unifying everything from the operating system and schedulers to drivers, dashboards, and monitoring.
TurbOS® delivers faster, reproducible performance that scales across edge systems, clusters, private clouds, and sovereign environments.
SUPPORTED HARDWARE

TurbOS® turns fragmented infrastructure into a cohesive computing environment— so teams can focus on results, not setup.
what is turbos®?
TurbOS® is a computing platform that unifies simulation and artificial intelligence (Al) workloads under one environment.
It replaces the patchwork of Linux builds, schedulers, and drivers that teams typically assemble by hand with a single, consistent image that runs everywhere - from clusters to private clouds.
Instead of configuring each machine manually, Turbos deploys a shared control plane that manages every node automatically.
Every system runs identical software, ensuring predictable performance, reproducible results, and effortless scaling across CPU and GPU resources.
Resources



Full Stack Simplicity
Includes everything required to run workloads: operating system, scheduler, drivers, libraries, and monitoring. No integration work or driver configuration is needed.
Reproducibility and Auditability
All nodes run from one master image so every workload executes in an identical software environment. Job logs and system states are stored centrally for traceability and verification.
Security and Trust
Designed and maintained by engineers with more than forty years of experience in high performance computing at national laboratory scale. Validated for export controlled and government regulated workloads.
Transparent Usage and Chargeback
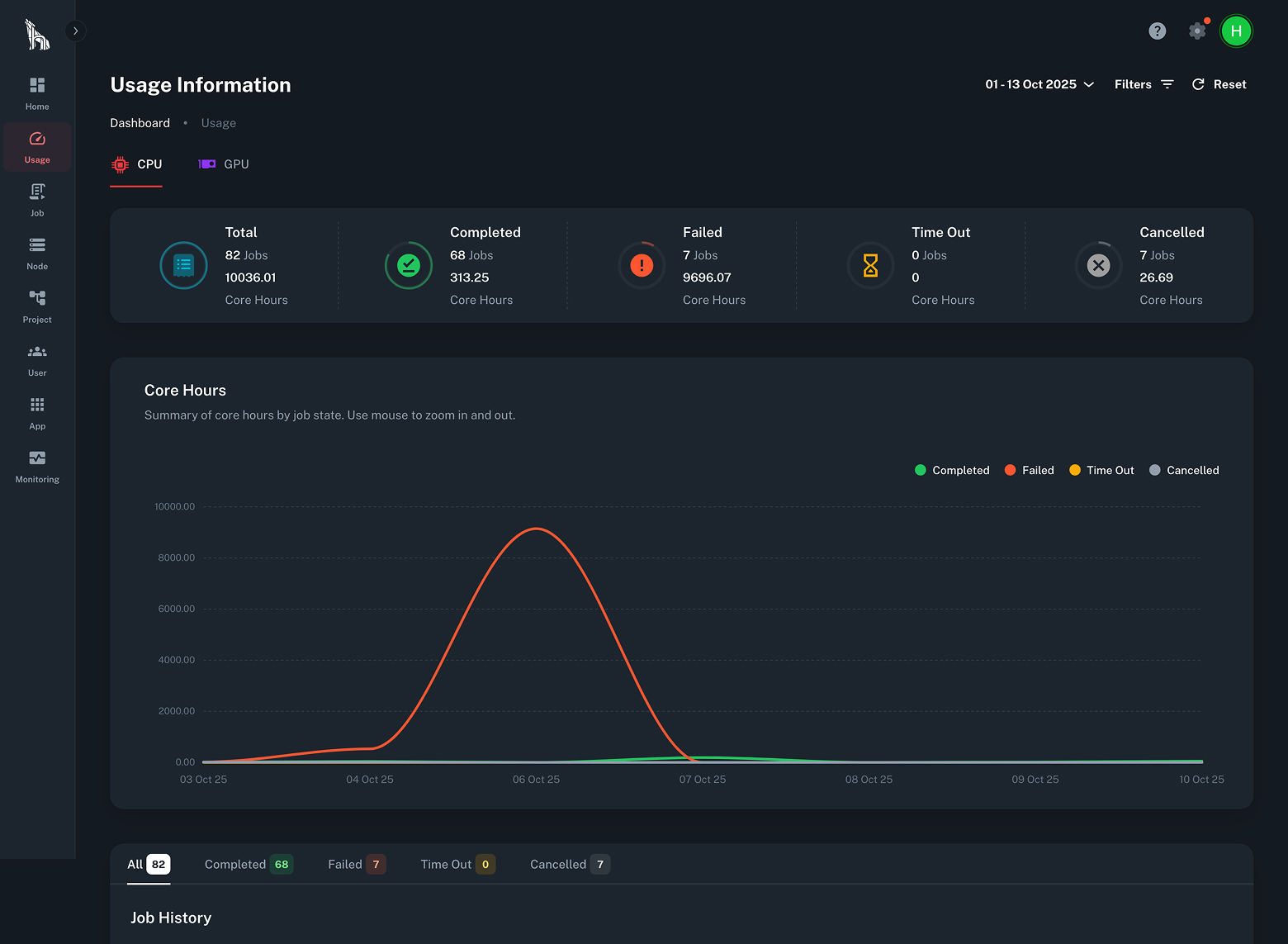
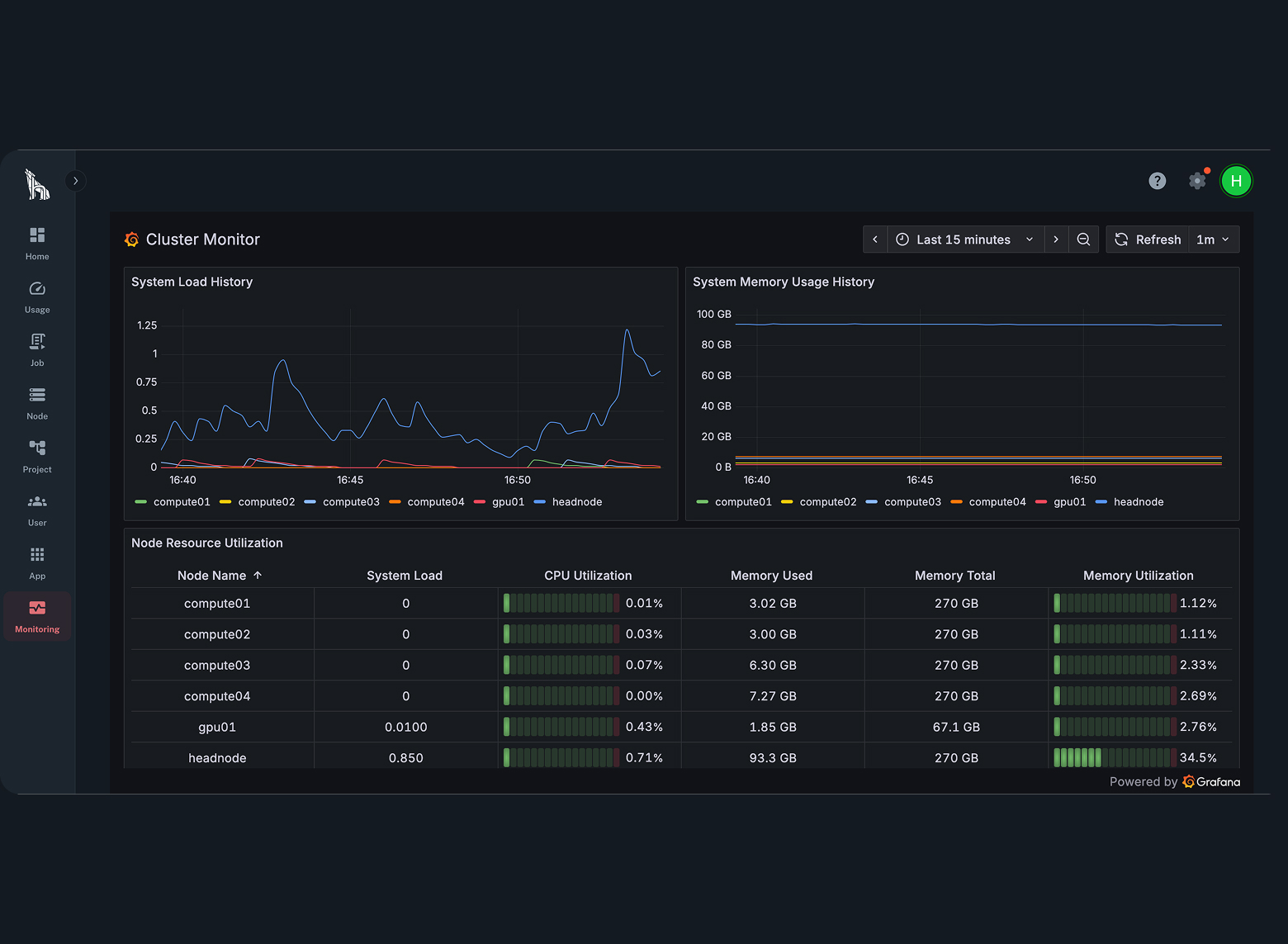
Built in reporting tracks GPU and CPU usage by user and project through the TurbOS® Dash interface. IT and leadership can view utilization metrics and export cost data directly from the dashboard.
Portable and Sovereign Ready
Runs on workstations, on premise clusters, and private or sovereign clouds with the same configuration. Supports export control, classified research, and air gapped environments without internet dependencies.
Workforce Multiplier
Researchers can submit jobs and monitor progress through the graphical interface without needing HPC administrators. IT teams retain full control of resource allocation and system visibility.

Features
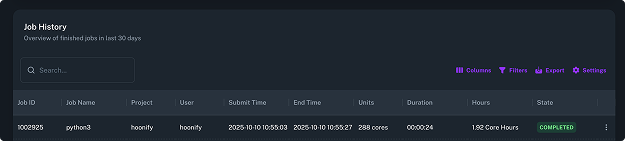
TurbOS® Dash gives every team clear visibility and control over their advanced simulation and AI computing platform. From engineers and researchers to IT administrators, every user can do in minutes what used to take hours by hand. It replaces the complexity of command-line management with a simple interface so you can launch jobs, monitor performance, and manage clusters in just a few clicks.
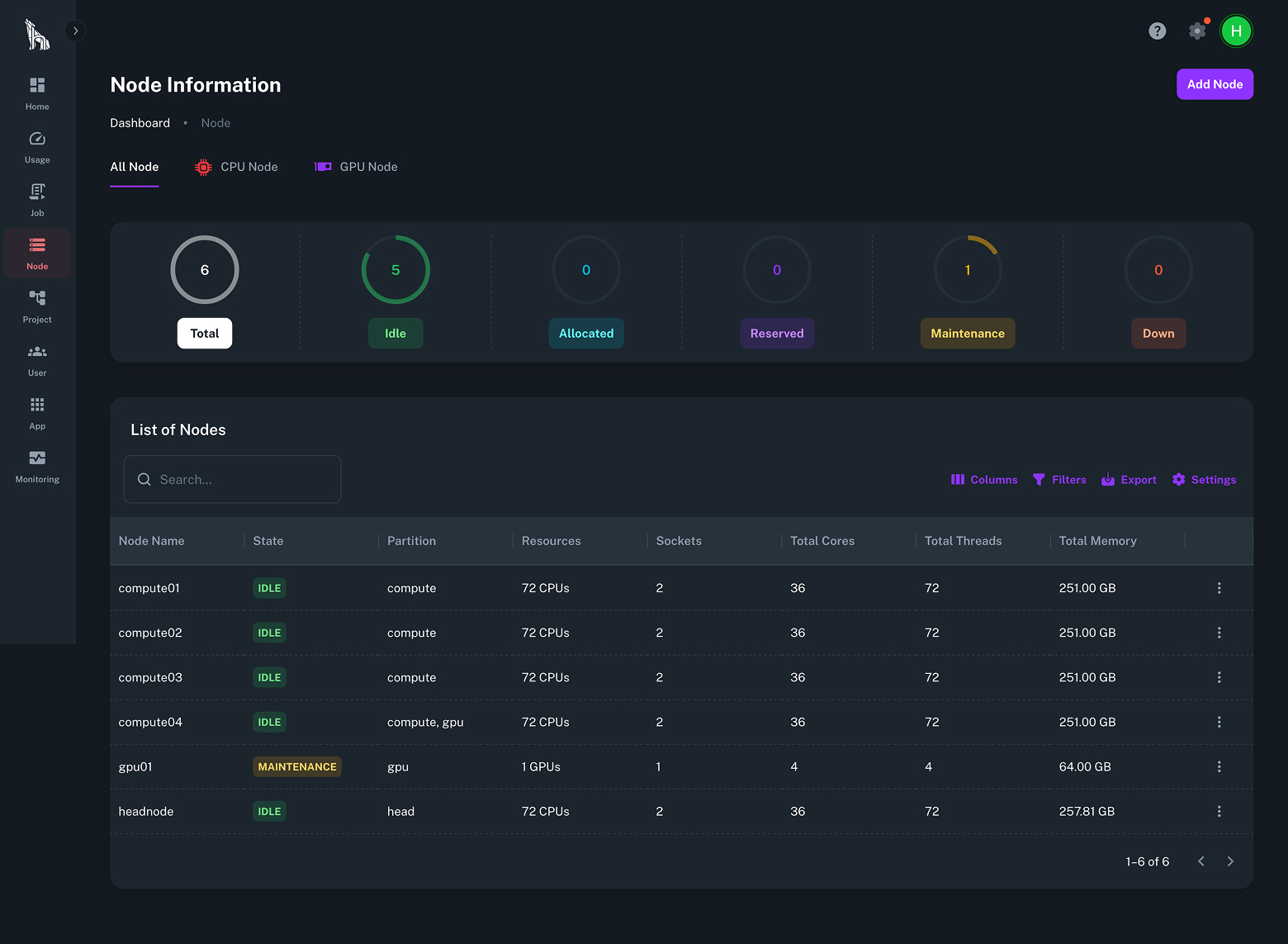
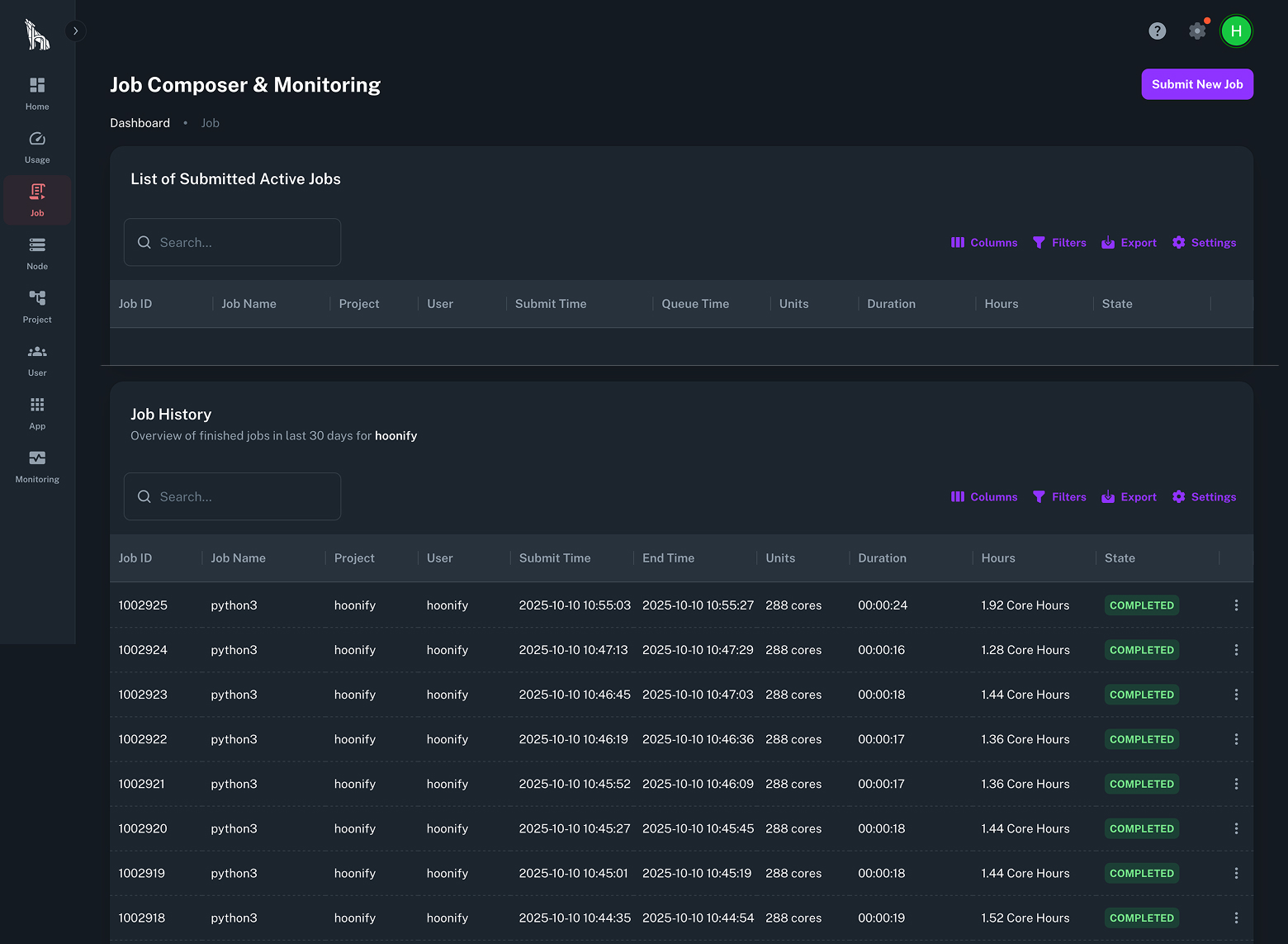
CPUs and GPUs in Parallel
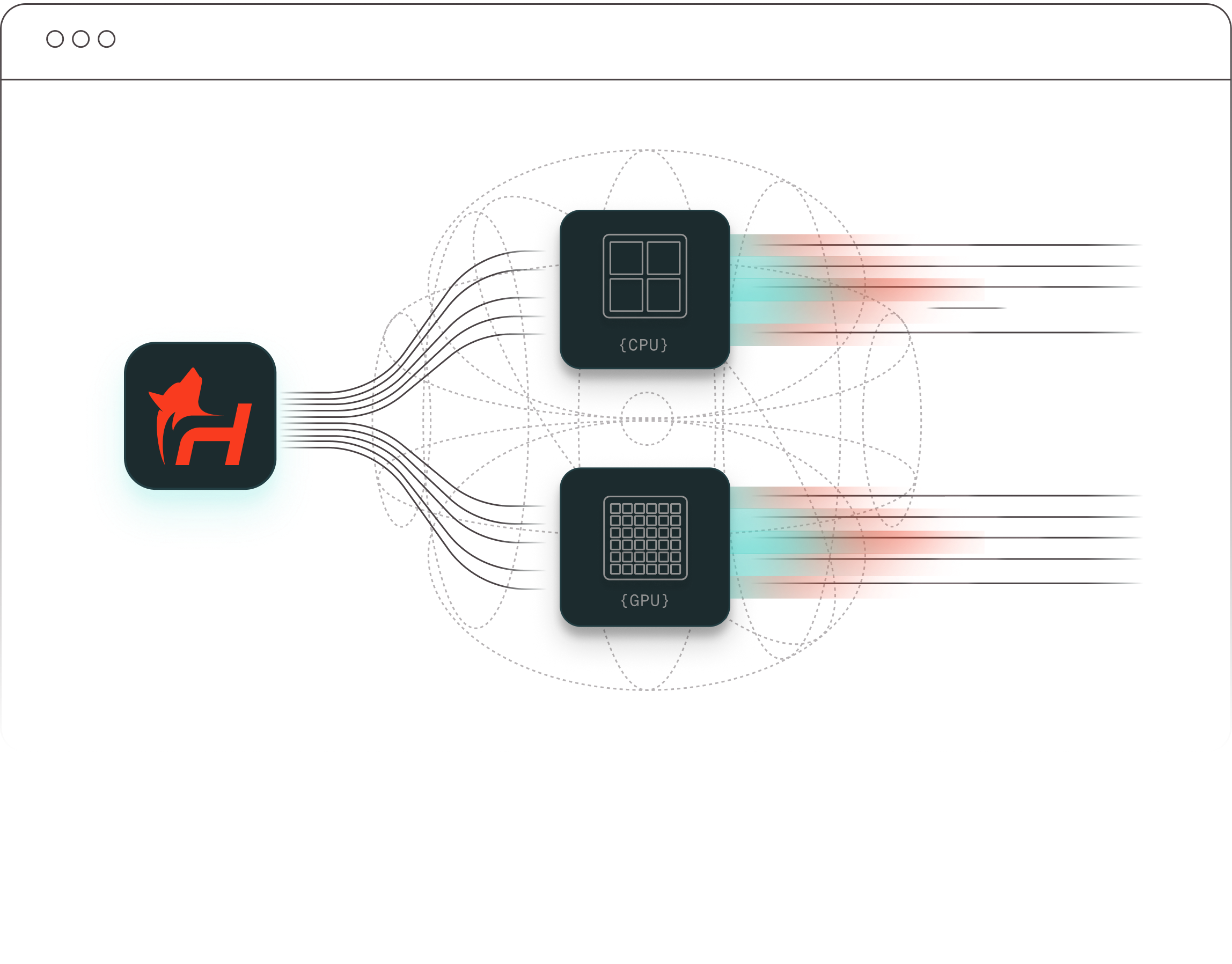
TurbOS® manages both CPU and GPU workloads through the Slurm scheduler and its runtime environment.
It automatically allocates jobs to the right processors based on requirements, ensuring balanced utilization and efficient performance for simulation, modeling, and AI training.

HOONIFY TURBOS / THE SOLUTION
From unstable builds to a reliable platform
Traditional systems are built manually, with each team configuring Linux, schedulers, and drivers on their own. Over time this creates version drift, package mismatches, and failed updates that slow work and break results.
TurbOS® removes those risks. It is built through a fully automated DevOps process that pulls trusted Linux bases, adds validated packages, runs continuous tests, and delivers one consistent image ready for any environment. The result is stability and reproducibility across every deployment.
How it works
DEPLOY
RUN WORKLOADS
Smart Resource Allocation & Processing
Post-Process & AI-Assisted Insight
Manage & Monitor


TESTIMONIALS
Optimization for Applications
TurbOS® simplifies how teams run simulation and AI workloads by creating optimized environments for every application. Each runs as intended with no manual setup or dependency issues.
Ready to Run Applications
Pre integrated and validated apps launch instantly in fully configured environments. The TurbOS Certified badge ensures reliability and performance across releases.
Integrate Your Own
Add and tune your own applications using built in tools while maintaining consistency and control.
Gain visibility, trust, and optimized performance on the TurbOS platform.
TurbOS® Supported Applications
The following applications are currently supported and optimized within TurbOS and we continue to add more. If you don’t see your application, let us know!
FAQs
TurbOS® is a full-stack HPC operating platform developed by Hoonify that unifies simulation and AI workloads in a single, consistent environment. It replaces the patchwork of Linux builds, job schedulers, drivers, and monitoring tools that teams typically configure manually with one validated image that runs identically across workstations, on-premises clusters, private clouds, and air-gapped facilities.
Engineers and researchers submit jobs and monitor results through TurbOS® Dash — a graphical interface that eliminates the need for command-line expertise or dedicated HPC administrators.
TurbOS® can be brought online in under an hour, on-premises or in a hosted private cloud. Deployment uses a fully automated process — there is no manual Linux configuration, driver installation, or scheduler tuning required. The platform arrives as a complete, validated software stack that is ready for real workloads from day one.
This stands in contrast to traditional HPC setups, which typically require days or weeks of manual configuration work before the first job can be submitted.
TurbOS® runs on standard x86-64 hardware from Intel and AMD, and supports NVIDIA and AMD GPUs. Our growing list of validated hardware partners include Dell, HP, Supermicro, 2CRSi, and Hypertec. The platform supports workstations, multi-node clusters, and private cloud infrastructure, allowing organizations to leverage existing hardware investments without procuring proprietary systems.
TurbOS® ships with a growing library of TurbOS® Certified applications that are pre-integrated, tested, and ready to run without additional configuration. Supported applications include Ansys Fluent, Ansys HFSS, OpenFOAM, LAMMPS, GROMACS, NAMD, LANL MCNP, SNL CTH, ORNL ADVANTG, CERNFLUKA, CFL3D, ALE3D, MATLAB, and GadgeT-4, among others.
Teams can also integrate their own applications using built-in tooling while maintaining environment consistency. The TurbOS® Certified partner program allows independent software vendors to validate and optimize their applications for the platform. Contact Hoonify for more details on how to join our partner program.
TurbOS® uses Slurm as its workload scheduler and runs on enterprise Linux distributions including Red Hat Enterprise Linux (RHEL) and Rocky Linux. The platform manages both CPU and GPU workloads through Slurm's scheduler and runtime environment, automatically allocating jobs to the appropriate processor type based on requirements.
Because TurbOS® is distributed as a single master image, every node in a deployment runs identical software, eliminating version drift and scheduler misconfiguration across sites.
Yes. TurbOS® is designed to operate without external network connectivity, making it suitable for export-controlled, classified, and sovereign computing environments. All required components — including the operating system, scheduler, drivers, libraries, and monitoring tools — are packaged within the deployment image. No internet access, cloud APIs, or external telemetry are required at runtime.
Software updates can be delivered via approved physical media and applied within isolated networks according to organizational security policy.
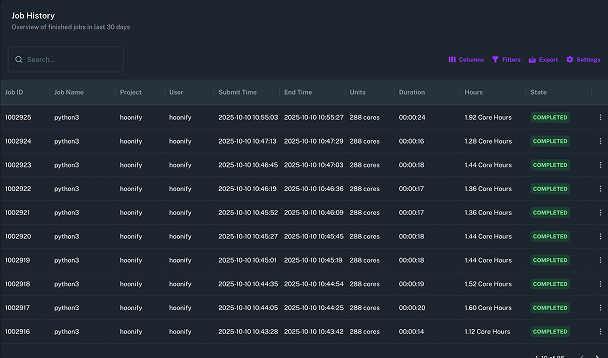
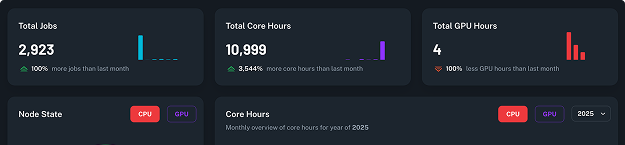
TurbOS® includes built-in usage tracking through TurbOS® Dash. IT administrators and program managers can filter resource consumption by user, project, and date range, and export cost data directly from the dashboard. GPU and CPU utilization is tracked per job, enabling accurate cost allocation across teams and departments.
This eliminates the need for third-party monitoring tools and gives leadership real-time visibility into platform spend without custom instrumentation.