
Clusters are ideal for research and engineering workloads that require heavy compute resources. TurbOS unifies these systems under one software environment so every node performs the same way, predictable, repeatable, and fully managed.
How it works
DEPLOY
RUN WORKLOADS
Smart Resource Allocation & Processing
Post-Process & AI-Assisted Insight
Manage & Monitor


KEY ADVANTAGES
Identical environment across all nodes
Simplified job scheduling and resource allocation
Centralized performance monitoring
Scalable architecture that grows with your workloads
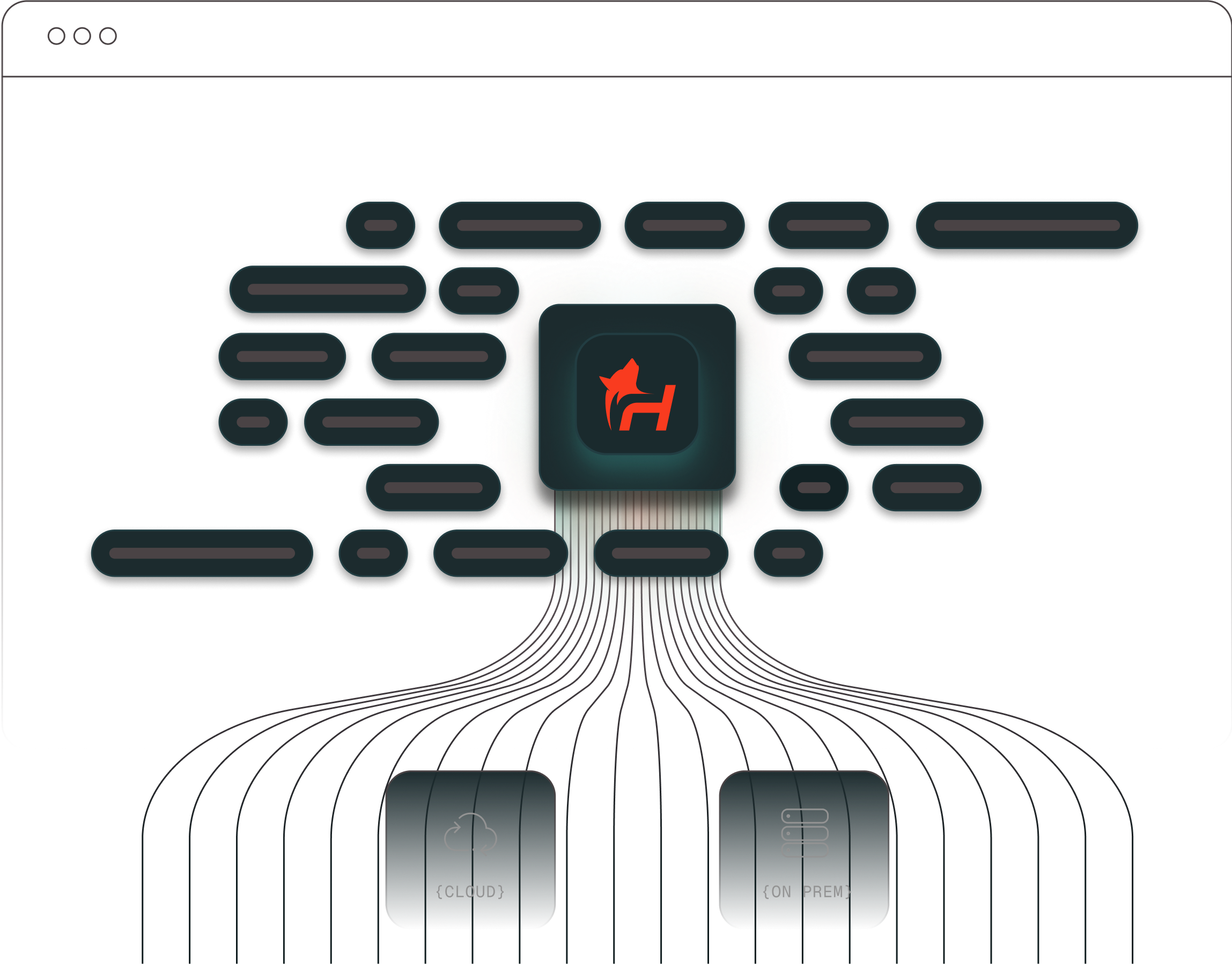
Cluster Architecture
Built for performance, scale, and simplicity. Every TurbOS cluster is organized into four core layers.
Built to Scale From One System to Thousands
Begin with one node or expand to a very large footprint. TurbOS keeps every system consistent as your cluster grows.
CPU Nodes
GPU Nodes
TurbOS® Supported Applications
The following applications are currently supported and optimized within TurbOS and we continue to add more. If you don’t see your application, let us know!
DEPLOYMENTS
Hoonify developed TurbOS® to give teams the control, reliability, and speed needed to meet mission goals securely and on time.
Edge Systems
Fast local testing and simulation.
Private Cloud
Secure in-facility operations.
Clusters
Consistent performance for large scale workloads.
FAQs
A TurbOS® Cluster is a multi-node high-performance computing environment managed by a single, consistent TurbOS® software image. Rather than configuring each compute node individually, TurbOS® deploys a shared control plane across all nodes — ensuring every system runs identical software, uses the same scheduler, and produces reproducible results.
Clusters are ideal for research and engineering teams that need to run large-scale simulation, AI, or scientific computing workloads that exceed the capacity of a single workstation. TurbOS® manages the full stack — operating system, Slurm scheduler, drivers, libraries, and monitoring — so teams can focus on results rather than infrastructure.
TurbOS® Clusters are designed for compute-intensive workloads that require parallelism, large memory, or GPU acceleration across multiple nodes. Common workloads include computational fluid dynamics (CFD), structural and materials simulation, molecular dynamics, Monte Carlo particle transport, electromagnetic modeling, and large-scale AI model training and inference.
The platform supports a growing library of TurbOS® Certified applications — including Ansys Fluent, OpenFOAM, LAMMPS, LANL MCNP, GROMACS, and others — that are pre-integrated and ready to run without additional configuration. Teams can also bring their own applications and tune them within the TurbOS® environment.
Every node in a TurbOS® Cluster boots from the same verified master image. This eliminates configuration drift — the gradual divergence in software versions, packages, and drivers that occurs when nodes are configured manually over time. Because every node runs identical software, workloads produce consistent, reproducible results regardless of which node they execute on.
TurbOS® is built through a fully automated DevOps process that pulls trusted Linux bases, adds validated packages, and runs continuous tests before delivering a single verified image. Updates are applied uniformly across all nodes, preventing the package mismatches and broken builds common in manually managed clusters.
TurbOS® uses Slurm as its workload scheduler, configured and managed through the Cluster Manager — the central coordination layer of every TurbOS® deployment. The Cluster Manager handles job queuing, resource assignment, user roles, and system-level coordination across all nodes.
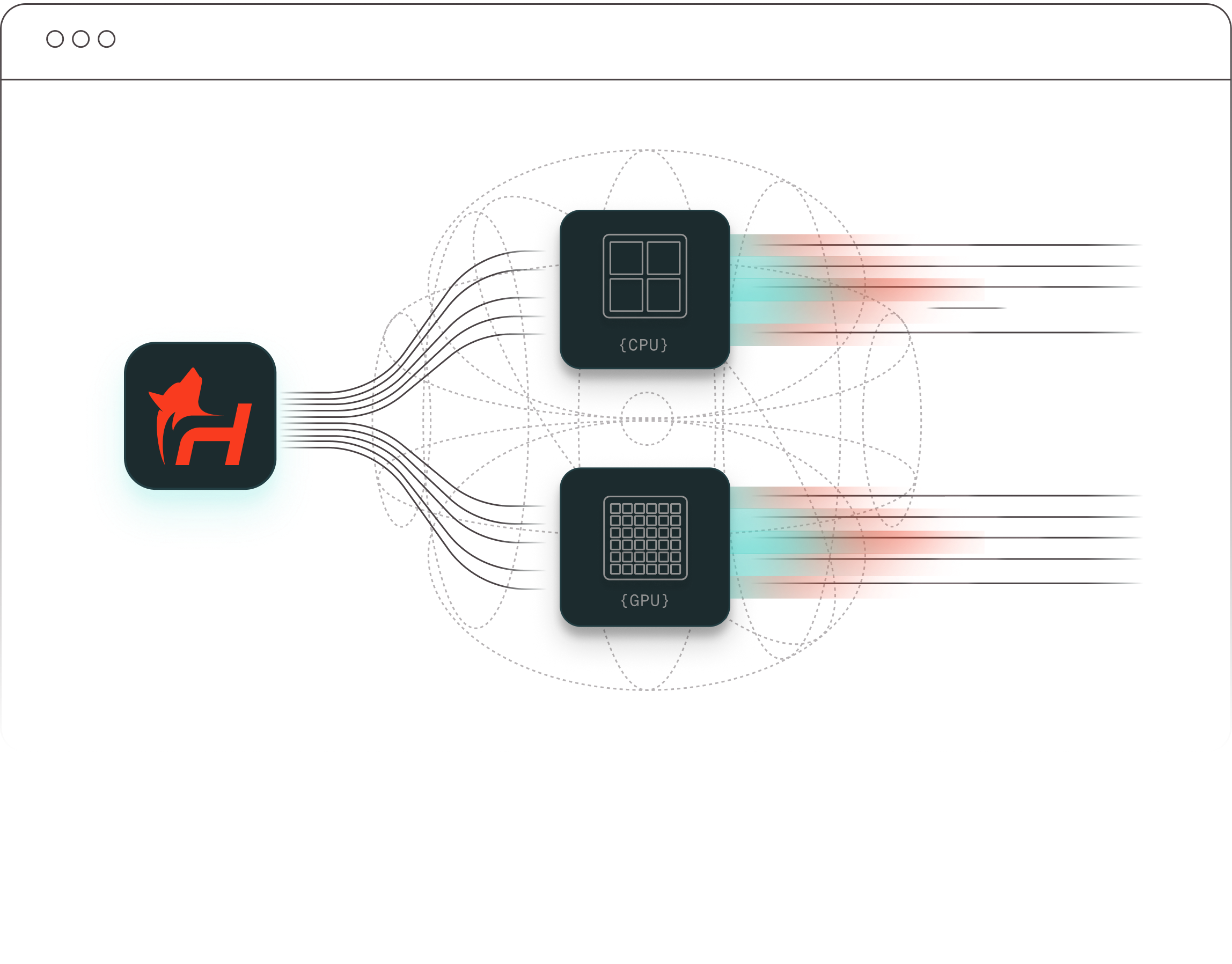
Most HPC engineers work directly in the terminal, and TurbOS® is built for that. All standard Slurm commands — including sbatch, squeue, sinfo, scancel, and srun — work exactly as expected. Nothing is removed or abstracted away. TurbOS® Dash is an additional graphical interface for engineers, researchers, and managers who prefer not to use the terminal, making the platform accessible to a broader team without changing how experienced HPC users work. Jobs are automatically allocated to CPU or GPU nodes based on requirements, ensuring balanced utilization and efficient throughput across the cluster.
TurbOS® Clusters are designed to scale from a single node up to very large multi-node footprints. The platform supports both CPU and GPU nodes within the same cluster, allowing teams to start small and expand as workload demands grow — without reconfiguring the software environment or retraining administrators.
Because every node runs from the same TurbOS® image, adding nodes does not introduce configuration complexity. New systems are brought online quickly and automatically join the managed environment with the same settings, scheduler configuration, and application stack as existing nodes.
Yes. TurbOS® is built to grow with your infrastructure. You can begin with one node and expand to a large cluster without changing the software environment or administrative workflows. Each new node is added to the existing TurbOS® control plane and immediately benefits from the same scheduling, monitoring, and management capabilities as the rest of the cluster.
TurbOS® also supports hybrid deployments, allowing on-premises clusters to be combined with private cloud resources for flexible scaling when workloads spike. This gives teams burst capacity without permanent hardware investment, while maintaining the same consistent TurbOS® environment across both on-prem and cloud nodes.
Yes. TurbOS® Clusters are fully capable of operating without external network connectivity, making them suitable for classified, export-controlled, and sovereign computing environments. All required components — including the operating system, Slurm scheduler, drivers, libraries, and monitoring tools — are packaged within the deployment image. No internet access, cloud APIs, or external telemetry are required at runtime.
The Cluster Manager, Application Layer, Storage Layer, and Compute Nodes all function within a completely isolated network. Software updates can be delivered via approved physical media and applied within controlled environments according to organizational security policy. TurbOS® has been designed and maintained by engineers with national laboratory experience, and is validated for export-controlled and government-regulated workloads.